


N叉树没有严格意义上的中序遍历。中序遍历通常用于二叉树,它是指先访问左子树,然后访问根节点,最后访问右子树。由于N叉树的节点可能有多个子节点,因此没有明确的“左”和“右”子树的概念,所以无法直接套用中序遍历的概念。
题目描述
给定一个 n 叉树的根节点 root ,返回 其节点值的 后序遍历 。
n 叉树 在输入中按层序遍历进行序列化表示,每组子节点由空值 null 分隔(请参见示例)。
示例 1:
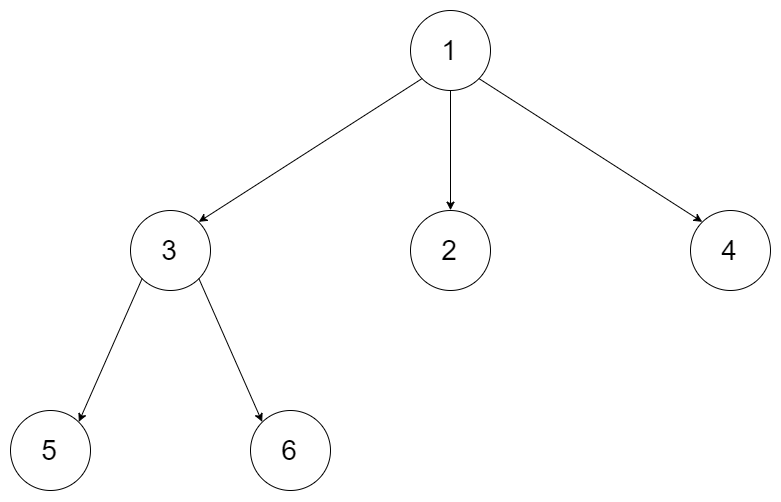
输入:root = [1,null,3,2,4,null,5,6] 输出:[5,6,3,2,4,1]
示例 2:
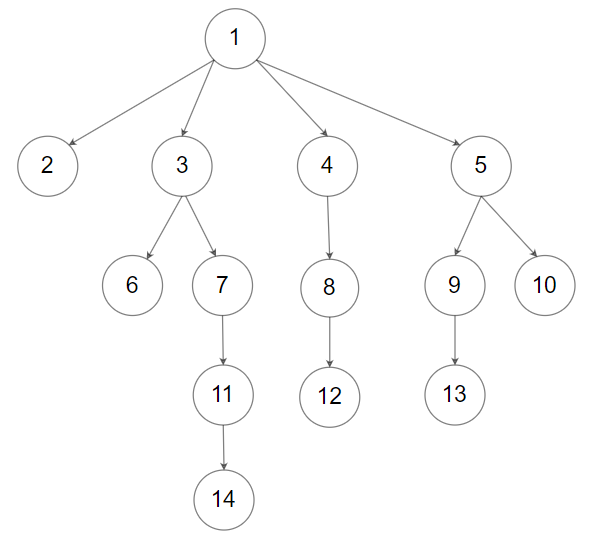
输入:root = [1,null,2,3,4,5,null,null,6,7,null,8,null,9,10,null,null,11,null,12,null,13,null,null,14] 输出:[2,6,14,11,7,3,12,8,4,13,9,10,5,1]
代码
"""
# Definition for a Node.
class Node:
def __init__(self, val=None, children=None):
self.val = val
self.children = children
"""
# 先序遍历 根节点->子节点
class Solution:
def preorder(self, root: 'Node') -> List[int]:
def dfs(node):
if not node: return
yield node.val
for child in node.children:
yield from dfs(child)
return [v for v in dfs(root)]
# 后序遍历 子节点->根节点
class Solution:
def postorder(self, root: 'Node') -> List[int]:
def dfs(node):
if not node: return
for n in node.children:
yield from dfs(n)
yield node.val
return [v for v in dfs(root)]yield 是一个关键字,通常用于 Python 中的生成器函数。它允许函数暂停执行并返回一个中间值,稍后可以继续执行。
每次调用生成器函数时,它会从上一次暂停的地方继续执行,并返回生成器中的下一个值。
这使得生成器可以有效地处理大量数据或者无限序列,而不会一次性将所有数据存储在内存中。
Comments NOTHING