

问题背景
部门在生产上有在使用Clickhouse数据库,主要场景为大数据实时主题,实时数仓建设,采用Flink +Clickhouse 结合的方式,通过Flink消费上游数据,进行ETL,并和其他维表流进行实时关联,将明细数据写入clickhouse,为下游BI报表提供服务,实现秒级查询响应。
环境版本
- Clickhouse version: 21.4.6.55 (official build)
- Zookeeper version: 3.7.0
集群读写流程架构图
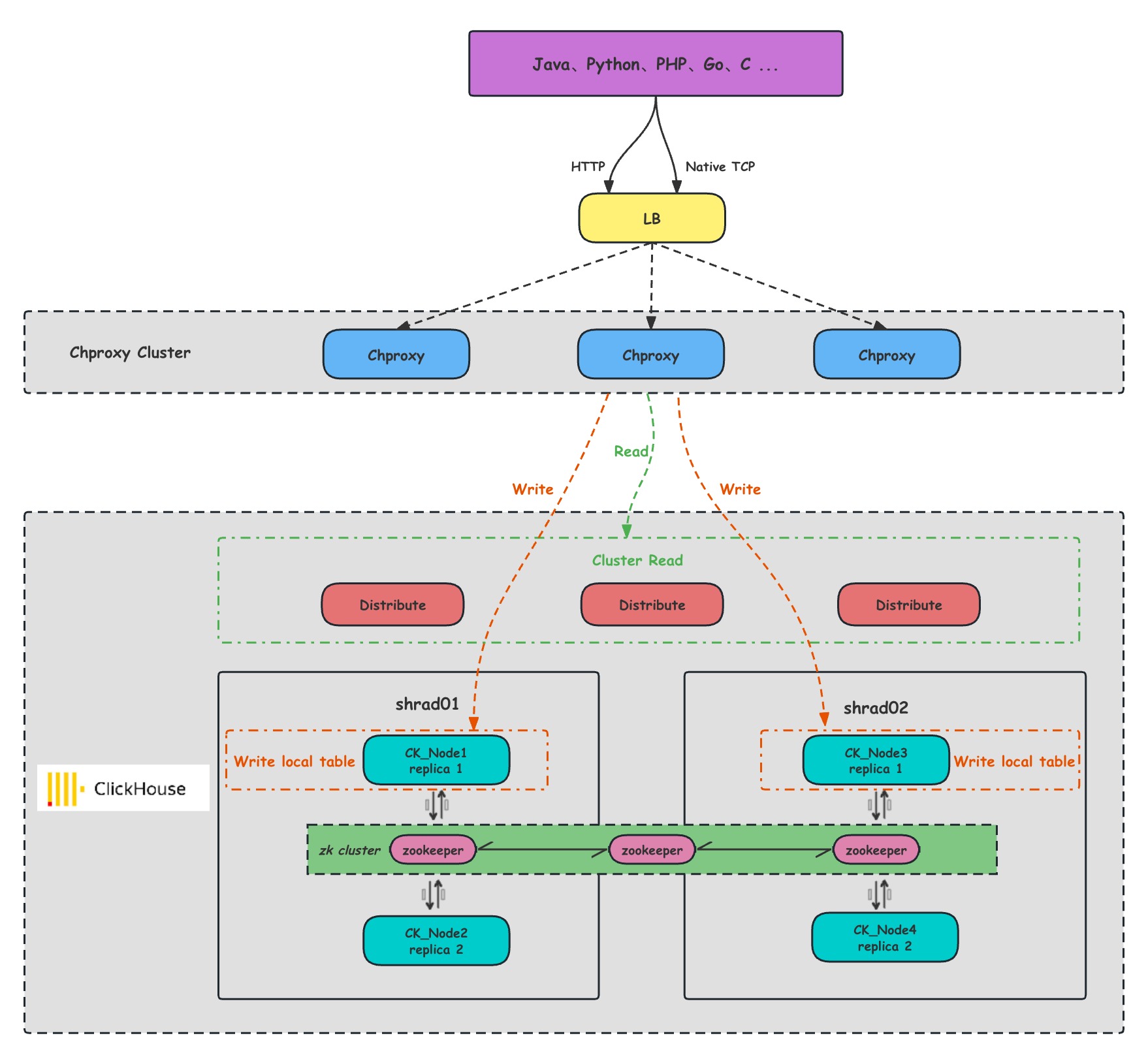
- LB:负载均衡组件
- Chproxy:用于ClickHouse集群和客户端之间充当中间层,用于负载均衡、故障转移和安全认证。
- Shard:集群内划分为多个分片或分组(Shard 0 … Shard N),通过 Shard 的线性扩展能力,支持海量数据的分布式存储计算。
- Ck_Node: 每个 Shard 内包含一定数量的节点(Node,即进程),同一 Shard 内的节点互为副本,保障数据可靠。ClickHouse 中副本数可按需建设,且逻辑上不同 Shard 内的副本数可不同。
- ZooKeeper : 集群所有节点对等,节点间通过 ZooKeeper 服务进行分布式协调。
问题反馈
业务在使用中,大部分是基于ReplicatedMergeTree引擎的表,业务通过数据库客户端对 Clickhouse 集群执行了修改表 TTL 的 DDL 操作后,出现了集群业务表只读不可写入的情况:
- DDL语句如下:
ALTER TABLE db.ads_user_bg_stat_30min ON CLUSTER 'cluster_bigdata_online' MODIFY TTL day + toIntervalDay(31);- 业务及Clickhouse错误中均出现错误:

ERROR 242 (00000) at line 2: Code: 242, e.displayText() = DB::Exception: Table is in readonly mode (zookeeper path: /clickhouse/path/../other_table) (version 21.4.6.55 (official build))
- 查看 zookeeper 状态
- 由于Clickhouse是使用zookeeper来存储元数据,并通过zookeeper实现注册和集群协调的。我们 Clickhouse 集群为4节点,Zookeeper集群部署的为是三节点(复用 Clickhouse的 节点)。猜测集群不可写应该和 Zookeeper 集群有关。查看 Zookeeper 集群日志,虽然进程还在,但是查看三个 Zookeeper 状态已经报错了,如下:
[bigdata-clickhouse-online bin]$ ./zkServer.sh status
ZooKeeper JMX enabled by default
...
...
Error contacting service. It is probably not running.至此,我们确定了是由于 Zookeeper 服务不可用导致了 Clickhouse 集群只读的问题。
Zoopkeeper 集群修复过程
尝试重新启动节点
三个节点重启后,发现出现了其他报错 java.io.IOException: Unreasonable length = 2398366 ,不能建立正确的leader 与 follower 关系,并且
注意: 这里走了一点弯路,有些网上文章提示通过在启动 zoopkeeper 的时候添加参数
-Djute.maxbuffer=6291456 可以规避掉 Unreasonable length 这个错误,但事实并不能解决此问题,并且可能对集群的使用会存在一定的风险,具体请参考:https://cloud.tencent.com/developer/article/1516691。

尝试使用此方法并没有实际解决我们的问题,继续尝试其他方法。
尝试修复zookeeper元数据
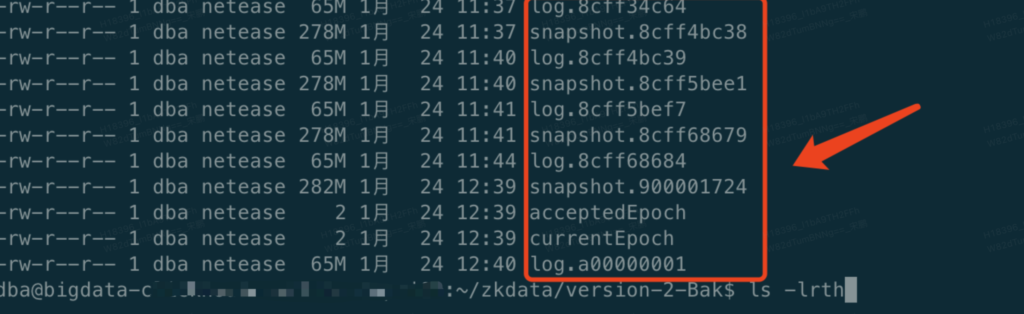
为了尽量恢复到 Clickhouse 集群正常前的状态。咨询了相关同事出现问题的大概时间,为了和zookeeper的snapshot.xxx和log.xxx文件时间进行核对,以便快速定位问题。
这里可以使用org.apache.zookeeper.server.LogFormatter 解析快照日志,但是zookeeper 从 3.5.5 版本之后,就取消的LogFormatter ,使用了一个更好的 TxnLogToolkit 工具,这个工具放置在了 bin/ 目录下,文件名是 zkTxnLogToolkit.sh。使用方式: zkTxnLogToolkit.sh log_file。
注意: 操作之前一定要备份一份完整的 Zookeeper 数据目录到备份文件夹。
这里定位到了 log.8cff68684文件中存在错误实例启动不起来的 Unreasonable length 错误,如下:
1/25/24 11:43:38 AM CST session 0x20853b92347000a cxid 0x29051aa0 zxid 0x8cff7a682 multi delete:q/clickhouse/dws_user_30min_incr_user_firm/replicas/bigdata-ck04/parts/20240124_3078_3078_0
1/25/24 11:43:38 AM CST session 0x20853b92347000a cxid 0x29051aac zxid 0x8cff7a683 multi delete:S/clickhouse/dws_user_30min_incr_user_firm/log/log-0009676538;check:I/clickhouse/dws_user_30min_incr_user_firm/replicas
Exception in thread "main" java.io.IOException: Unreasonable length = 2409496
at org.apache.jute.BinaryInputArchive.checkLength(BinaryInputArchive.java:166)
at org.apache.jute.BinaryInputArchive.readBuffer(BinaryInputArchive.java:127)
at org.apache.zookeeper.server.persistence.TxnLogToolkit.dump(TxnLogToolkit.java:202)
at org.apache.zookeeper.server.persistence.TxnLogToolkit.main(TxnLogToolkit.java:121)移除问题数据文件,尝试恢复 Zookeeper 集群状态
1月 25 16:09 log.8cff5bef7
1月 25 16:09 snapshot.8cff68679定位到问题文件,于是决定将 Zookeeper 的这个时间点以后的 snapshot.xxx 快照文件和 log.xxx 日志文件移到备份目录后再次重启。如果没有时间逐个分析文件可以把 snapshot.xxx 文件和 log.xxx 一个一个移向备份文件夹并重新尝试重启 ,重启后还是报 “Unable to load database on disk. Unreasonable length - ” 的错误就将三个节点的Clickhouse 进程都停掉,继续将 snapshot 快照文件往前删后重启 Zookeeper,直到没有这个报错。(不过需要评估集群最近正常状态的时间,不要恢复到过早的时间状态,可能元数据会差距过大)。我们这里由于分析了日志文件,知道问题出在哪个日志文件内,所以将有问题的文件移除数据目录,重启 Zookeeper 集群状态就恢复正常了。
Zookeeper 集群恢复后,开始尝试启动 Clickhouse。
Clickhouse 集群恢复
尝试启动节点,由于事务日志缺失了一个,可能会使得 Clickhouse 与 Zookeeper 元数据出现不一致的情况,那么就尝试启动节点让问题暴露出来,确实均不能正常启动,报错如下:The local set of parts of table xxx doesn’t look like the set of parts in ZooKeeper
按此报错分析,是本地的数据对不上zookeeper上的数据,此次报错涉及两张表,假设分别为 t1,t2 表。此处处理步骤参考技术博客推荐方式,大概步骤可以分为 3 步。
备份问题表的表数据及元数据
备份移走问题节点的表数据到其他目录:这里既要备份移走表的数据和表结构的 metadata,下面是备份 bigdata数据库下的表 t1,t2 数据到 /home/dba/backup 目录下
# 备份表的数据
mv /clickhouse/data/bigdata/t1 /home/dba/ck_backup/
# 备份表结构metadata
mv /clickhouse/metadata/bigdata/t1.sql /home/dba/ck_backup获取问题表在 Zk 中的路径(两种情况)
# 获取表的zk path
select zookeeper_path from system.replicas where database='bigdata' and table='t1';
#获取对应节点的replica_num , 可以直接从ck的配置文件中查到
SELECT replica_num,host_name FROM system.clusters;- 如果存在 Clickhouse 节点没有挂掉,可以尝试以下方式获取 t1,t2 表的 Zookeeper 路径。
- 由于我们此次 4 个节点均无法正常启动实例,所以需要参考 Clickhouse 错误日志中报错的 Zookeeper 路径去查看
2024.01.25 16:11:30.713108 [ 52850 ] {} <Error> Application: Caught exception while loading metadata: Code: 231, e.displayText() = DB::Exception: The local set of parts of table portal.adm_news_mysql_wallet_transactions_local (64d63619-d1b8-4bc0-8544-3d08bf2975c9) doesn't look like the set of parts in ZooKeeper: 1.41 thousand rows of 2.56 thousand total rows in filesystem are suspicious. There are 3 unexpected parts with 1407 rows (3 of them is not just-written with 1407 rows), 0 missing parts (with 0 blocks).: Cannot attach table `bigdata`.`t1` from metadata file /data/clickhouse_data/store/bb4/bb436a61-7716-4dd9-a250-17c17bff9927/t1.sql from query ATTACH TABLE bigdata.t1 UUID '64d63619-d1b8-4bc0-8544-3d08bf2975c9' (`id` Int64 COMMENT '主键ID', ..., `channel` String COMMENT '来源渠道') ENGINE = ReplicatedMergeTree('/clickhouse/tables/01/t1', '{replica}') PARTITION BY toYYYYMMDD(toDateTime(update_time)) ORDER BY id TTL create_time + toIntervalDay(3) SETTINGS index_granularity = 8192: while loading database `portal` from path /data/clickhouse_data/metadata/portal, Stack trace (when copying this message, always include the lines below):按日志提示,在 Zookeeper 中删除副本问题目录
- 按上述日志提示,在 Zookeeper 中确定该 t1及t2 表副本数据目录并删除
ls /clickhouse/tables/01/t1
[columns, flags, host, is_active, is_lost, log_pointer, max_processed_insert_time, metadata, metadata_version, min_unprocessed_insert_time, mutation_pointer, parts, queue]- 删除表的副本数据
deleteall <zookeeper_path>/replicas/<replica_num>重新创建副本表并导入备份数据
还记得我们刚刚备份的表数据和 metadata 目录的建表语句吧,备份目录下的文件分别为:
dba@bigdata-clickhouse-online:/data/backup$ ls -lh
lrwxrwxrwx 1 dba dba 68 7月 5 2023 t1 -> /path_to_clickhouse_datadir/store/21b/21bc255a-03ca-4bad-8375-eda8fbcf4dbd
-rw-r----- 1 dba dba 733 7月 5 2023 t1.sql
lrwxrwxrwx 1 dba dba 68 7月 5 2023 t2 -> /path_to_clickhouse_datadir/store/64d/64d63619-d1b8-4bc0-8544-3d08bf2975c9
-rw-r----- 1 dba dba 758 7月 5 2023 t2.sql建表语句处理并重建创建
ATTACH TABLE _ UUID '21bc255a-03ca-4bad-8375-eda8fbcf4dbd'
(
`id` Int64 COMMENT '主键ID',
...
...
`create_time` DateTime COMMENT '创建时间',
`update_time` DateTime COMMENT '更新时间'
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/t1', '{replica}')
PARTITION BY toYYYYMMDD(toDateTime(update_time))
ORDER BY id
TTL create_time + toIntervalDay(3)
SETTINGS index_granularity = 8192;ATTACH TABLE _ UUID 语句中,将 ATTACH 变为 CREATE,UUID是表的唯一标识符。将 UUID 变为表名重新分别在不通实例创建表,由于此次是在处理问题,所以单个 Clickhouse 实例本地表是单独创建的,不然也可以使用 On cluster xxxx 语法创建集群表,更改后如下:
CREATE TABLE t1 [ON CLUSTER cluster]
(
`id` Int64 COMMENT '主键ID',
...
...
`create_time` DateTime COMMENT '创建时间',
`update_time` DateTime COMMENT '更新时间'
)
ENGINE = ReplicatedMergeTree('/clickhouse/tables/{shard}/t1', '{replica}')
PARTITION BY toYYYYMMDD(toDateTime(update_time))
ORDER BY id
TTL create_time + toIntervalDay(3)
SETTINGS index_granularity = 8192;重新 Attach 数据目录数据
我们备份的目录中还有一个 t1 -> /path_to_clickhouse_datadir/store/21b/21bc255a-03ca-4bad-8375-eda8fbcf4dbd,这个目录中存储的就是表数据了,刚刚已经重新把问题表创建好,现在要尝试将备份时间点的数据灌入表内,查看目录下文件:
drwxr-x--- 2 dba netease 4.0K 1月 25 12:41 20240121_0_287_100
...
...
drwxr-x--- 2 dba netease 4.0K 1月 25 13:04 20240124_149_149_0
drwxr-x--- 2 dba netease 4.0K 7月 5 2023 detached
-rw-r----- 1 dba netease 1 7月 5 2023 format_version.txt其中 20240121_0_287_100 ~ 20240121_0_287_100 为数据,已知现数据目录为 /path_to_ckdata/bigdata/t1/,我们要将它们 mv 到目前空表的数据目录的 detached 目录下,并生成 ALTER TABLE ... ATTACH PART 语句,在集中每个 Shard的其中一个副本执行语句,副本间会自动同步数据。
mv 202401* /path_to_ckdata/bigdata/t1/detached
cd /path_to_ckdata/bigdata/t1/detached
for dir in 202401*; do
echo "ALTER TABLE t1 ATTACH PART '$dir';"
done输出并在 Clickhouse 执行语句:
ALTER TABLE t1 ATTACH PART '20240121_0_287_100';
...
...
ALTER TABLE t1 ATTACH PART '20240124_149_149_0';至此,线上集群的使用恢复正常,业务侧面已经没有报错。
注意: 目前只是集群恢复到了正常的状态,但是由于 zk 恢复的时候我们跳过了一个事务日志,所以可能会有数据不准确的情况,如果存在核心表,或者计算结果数据十分敏感的表,建议与业务沟通进行数据核对,我们此次业务侧具备数据修复的逻辑,为了数据准确,针对当天某些实时计算场景的数据表进行了重新消费写入。
Clickhouse集群恢复步骤归纳
- 在 Clickhouse 问题节点清理掉表数据和表结构
- 在 Zookeeper 找到对应节点的表的副本数据并删除
- 在 Clickhouse 问题节点重新建 ReplicatedMergeTree 表,然后 Attach 备份数据等待 Clickhouse 自动同步数据。
Clickhouse 后续报错处理
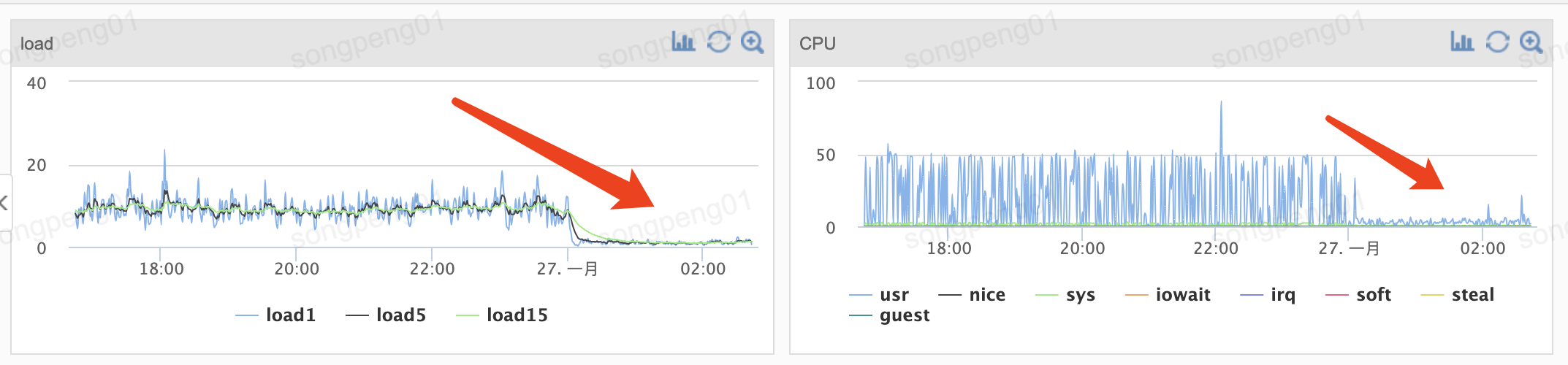
虽然目前环境正常了,但是观察发现,Clickhouse 服务器恢复后,CPU、Load 指标对比故障前会有比较大的上涨,查看 Clickhouse Error Log,发现很多 Warning 如下:
2024.01.26 00:04:56.720599 [ 7117 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Found parts with the same min block and with the same max block as the missing part f77c0fb339c212fc7a3809e0950c0d9a_3099_3111_2. Hoping that it will eventually appear as a result of a merge.
2024.01.26 00:04:56.720917 [ 7154 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Checking part 17c6d5f35f96ede2ec17b5d81fd426c8_0_3105_744
2024.01.26 00:04:56.721816 [ 7154 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Checking if anyone has a part 17c6d5f35f96ede2ec17b5d81fd426c8_0_3105_744 or covering part.
2024.01.26 00:04:56.724531 [ 7154 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Found parts with the same min block and with the same max block as the missing part 17c6d5f35f96ede2ec17b5d81fd426c8_0_3105_744. Hoping that it will eventually appear as a result of a merge.
2024.01.26 00:04:56.725418 [ 7123 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Checking part 6410bfa227611c4afa238149caa02bdc_0_3103_807
2024.01.26 00:04:56.726452 [ 7123 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Checking if anyone has a part 6410bfa227611c4afa238149caa02bdc_0_3103_807 or covering part.
2024.01.26 00:04:56.729180 [ 7123 ] {} <Warning> bigdata.t1 (ReplicatedMergeTreePartCheckThread): Found parts with the same min block and with the same max block as the missing part 6410bfa227611c4afa238149caa02bdc_0_3103_807. Hoping that it will eventually appear as a result of a merge.这是由于之前的 Zookeeper 元数据丢失导致的 Missing part 错误。既然数据已经重新生成,那么针对这种报错我们可以把错误的 Zookeeper 数据清理掉,避免在 Merge 之前一直 Checking 数据,这对于性能会有很大的损耗。
修复报错步骤
- 查找 system.replication_queue 表中的相关信息:
SELECT * FROM system.replication_queue WHERE create_time < now() limit 5;
┌─database─┬─table─────────────┬─replica_name─────────┬─position─┬─node_name────────┬─type─────┬─────────create_time─┬─required_quorum─┬─source_replica─┬─new_part_name────────┬─parts_to_merge─┬─is_detach─┬─is_currently_executing─┬─num_tries─┬─last_exception───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┬───last_attempt_time─┬─num_postponed─┬─postpone_reason─┬──last_postpone_time─┬─merge_type─┐
│ bigdata │ t1 │ CK-02 │ 0 │ queue-0000023053 │ GET_PART │ 2022-07-27 17:08:58 │ 0 │ │ 20220727_0_1691_391 │ [] │ 0 │ 0 │ 4103 │ Code: 234. DB::Exception: No active replica has part 20220727_0_1691_391 or covering part. (NO_REPLICA_HAS_PART) (version 21.4.6.55) │ 2024-01-25 01:30:11 │ 0 │ │ 1970-01-01 08:00:00 │ │
│ bigdata │ t1 │ CK-02 │ 0 │ queue-0000110719 │ GET_PART │ 2022-07-27 17:09:04 │ 0 │ │ 20220727_0_7553_5995 │ [] │ 0 │ 0 │ 4659 │ Code: 234. DB::Exception: No active replica has part 20220727_0_7553_5995 or covering part. (NO_REPLICA_HAS_PART) (version 21.4.6.55) │ 2024-01-25 01:30:11 │ 0 │ │ 1970-01-01 08:00:00 │ │报错数据出现在 last_exception

- 获取 Zookeeper 存储路径:
SELECT replica_path || '/queue/' || node_name, last_exception FROM system.replication_queue JOIN system.replicas USING (database, table) WHERE create_time < now();
┌─concat(replica_path, '/queue/', node_name)───────────────────────────────────────┬─last_exception───────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┐
│ /path_to_replica/replicas/queue/queue-0000023053 │ Code: 234. DB::Exception: No active replica has part 20220727_0_1691_391 or covering part. (NO_REPLICA_HAS_PART) (version 21.4.6.55) │
│ /path_to_replica/replicas/queue/queue-0000110719 │ Code: 234. DB::Exception: No active replica has part 20220727_0_7553_5995 or covering part. (NO_REPLICA_HAS_PART) (version 21.4.6.55) │
└─────────────────────────────────────────────────────────────┴──────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────────┘- 在 ZooKeeper 中删除上面有问题的路径节点:
clickhouse-client --user bigdataonline --password pwd4ck --host xxxx --port xxxx --query "SELECT replica_path || '/queue/' || node_name FROM system.replication_queue JOIN system.replicas USING (database, table) WHERE create_time < now() AND last_exception LIKE '%No active replica has part%'" | while read i; do ./zkCli.sh -server zk_server_ip:port delete $i ; done- 所有节点处理完错误后重启副本
SYSTEM RESTART REPLICAS对所有副本执行此操作,直到不再存在此报错。
至此,全部问题处理完毕,Clickhouse服务器的负载也慢慢恢复正常。
问题总结与思考
Zookeeper
- ZooKeeper通过在每个事务提交时创建快照文件和事务日志文件来持久化数据。当ZooKeeper启动时,它会先加载最后一个快照文件,然后将事务日志文件中的事务应用到内存数据库中,从而使内存中的数据库恢复到最新状态。因此,只需保留最后一个快照文件和事务日志文件,ZooKeeper就可以正常启动并保留所有正确的数据。
- 一般来讲 Zookeeper副本通关多副本部署,服务是较为可靠的,但是此次事件的情况说明,除了基础的端口及进程监控,还需要关注服务的状态,此次事件进程和端口均存在,但是服务的状态已经不正常了 Error contacting service. It is probably not running 所以,后续还需要对状态多加关注,以快速追溯到故障源头,降低服务的故障时间。
- 掌握了zkTxnLogToolkit.sh工具对 Zookeeper 的事务日志进行分析,找到服务不能启动的关键原因。
- 注意 ZooKeeper 集群负载,如果配置不当,可能会导致响应时间延迟,从而影响ClickHouse集群中DDL操作的同步。
Clickhouse
- 翻阅了很多资料,官网 Github 上也有相关 Issue 反馈相关问题,但都并没有阐述出此次问题的具体原因,多数也只是讲DDL On Cluster的语法,偶发会导致此类问题。原因可能如下:
- ZooKeeper 的性能瓶颈:如果ZooKeeper集群本身的负载很高,或者配置不当,可能会导致响应时间延迟,从而影响ClickHouse集群中DDL操作的同步。
- 网络问题:分布式系统中的网络问题可能导致ZooKeeper的节点之间的通信中断或延迟,这可能会影响DDL命令的同步。
- ZooKeeper的会话超时:如果ClickHouse与ZooKeeper之间的会话由于某种原因被中断,也可能由于会话超时而导致同步问题。
- ZooKeeper状态不一致:在极端情况下,如ZooKeeper集群的大多数节点不可用,可能会导致状态不一致,从而影响DDL操作的同步,所以需要加强 Zookeeper集群监控项,例如节点状态监控,而不仅仅是监控进程和端口。
- 很多数据不一致的问题,都可以通过干掉副本数据和元数据, 然后让Clickhouse 自己再重新自动同步的方法来解决。
该如何规避此类问题
- 在执行 ALTER TABLE 操作时,避免频繁的并发操作,尽量在业务低峰期执行 ALTER TABLE 来减少并发操作的影响。
- 可以将 Alter Table ... On Cluster 语句变成单个 Local 表串行执行,尤其针对单表数据量大、Shard较多的场景,避免并发 DDL 在短时间内对 Zookeeper造成过大压力。
- 在使用 ClickHouse 的 ReplicatedMergeTree 表引擎,可以尽量启用分区表来增强表的可靠性和稳定性,以减少元数据损坏的风险。
- 发起操作尽量在服务器局域网内,不要通过 hyvpn 使用客户端执行此类 DDL 操作,避免网络不稳定对Zookeeper 造成的影响。
- 确保集群中的网络连接稳定,减少网络故障对元数据更新的影响。
- Zookeeper的日志及数据目录尽量部署在 SSD 磁盘,SSD 磁盘具有更低的访问延迟和更快的数据读写速度,而且可以提供更高的吞吐量,这对于 Zookeeper 的数据访问和元数据更新等操作来说非常有利。
- 加强 Zookeeper 服务的监控项,可以针对日志中的关键字进行过滤及报警,可以及时发现并解决可能导致元数据损坏的问题。
参考文章
- 关于zookeeper写入数据超过1M大小的踩坑记
- 查看zookeeper事务日志
- ZooKeeper上数据错乱导致ClickHouse启动失败问题
- [jira] [Comment Edited] (ZOOKEEPER-2553) ZooKeeper cluster unavailable due to corrupted log file during power failures -- java.io.IOException: Unreasonable length
- Zookeeper 客户端基础命令使用
- clickhouse断电后数据丢失 warning - Hoping that it will eventually appear as a result of a merge
- 一条DDL引发的ClickHouse集群故障实录
- 官方文档 Data Replication
- Removing lost parts
- Parts consistency
- Some merges may stuck #10368
- Problem with merges if some replica stopped #2755
- Anyway to manually fix Metadata on replica is not up to date with common metadata in Zookeeper? #17455
- ClickHouse官方文档
Comments NOTHING