



1、冒泡排序
冒泡排序是一种简单的排序算法。
工作原理:重复地遍历要排序的列表,比较每对相邻项,如果它们的顺序错误就把它们交换过来。
用从小到大的排序举例,先比较第1和第2,再比较第2和第3,再比较第3和第4,依次对比,每一对比过程中如果大的数在前,则两个值位置互换。
时间复杂度最好为O(n),最坏为O(n2),其中n是要排序的元素个数
空间复杂度为O(1),因为它只需要固定的额外空间来进行元素交换,与待排序数据量无关。

def bubbleSort(arr):
for i in range(len(arr) - 1): # 来回推len(arr)-1次 i就是已经排序完成了多少到最后
for j in range(len(arr) - i - 1): # 每一遍都会把未排序部分中最大的推到后面 橙色已排序的部分不需要再排了 故-i
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j] # 大的往后排 置换数值
return arr
if __name__ == '__main__':
arr_li = [1, 3, 9, 4, 0, 2, 7, 5, 8, 6]
print(bubbleSort(arr_li))2、选择排序
选择排序是一种简单且直观的排序算法。
工作原理是:首先在未排序序列中找到最小(或最大)元素,然后将其放到已排序序列的首部或末尾。重复这个过程,直到整个序列有序。这种算法的时间复杂度为O(n2),不需要额外的空间,是一种不稳定的排序算法。
它和冒泡类似,每一次大遍历都是把最大或最小的放置在首部或尾部(橙色部分),需要length-1次大遍历,每次大遍历中有length-1-i次小遍历(i是已排元素个数,也是已经大遍历的次数)
选择排序的时间复杂度为O(n2),空间复杂度为O(1)。
def selectionSort(arr):
for i in range(len(arr) - 1):
minInd = i # 放置最小值的下标
for j in range(i + 1, len(arr)): # 跳过已经排序好的前i个 每次都到len(arr)最后一个元素
print(j)
if arr[j] < arr[minInd]:
minInd = j
# 每一次大遍历后 对比剩余部分最小值和遍历起始下标值
if minInd != i:
arr[i], arr[minInd] = arr[minInd], arr[i]
return arr
if __name__ == '__main__':
arr_li = [1, 3, 9, 4, 0, 2, 7, 5, 8, 6]
print(selectionSort(arr_li))3、插入排序
插入排序是一种简单且直观的排序算法。
工作原理:依次从未排序元素的首位(或尾部)取出一个元素,将与已排序部分逐个对比,直到满足条件,将取出的元素放置在最后一次对比元素前,重复以上步骤直到未排序元素都被插入并排好序为止。
同冒泡排序时空复杂度,时间复杂度为最好为O(n),最坏为O(n2),,空间复杂度为O(1)。
def insertionSort(arr):
for i in range(len(arr)): # 大遍历次数len(arr)
current = arr[i] # 每次拿出一个current数组 依次和前面的作比较
preInd = i - 1 # current要和这个下标的值对比 第一次是和下标-1的对比 即直接将current放在preInd前(作为排序好的首位)
while preInd >= 0 and arr[preInd] > current:
arr[preInd + 1] = arr[preInd]
preInd -= 1 # 继续往前对比
arr[preInd + 1] = current # 直到前面没有比current大的了 将current放进刚对比的arr[preInd]前
return arr
if __name__ == '__main__':
arr_li = [1, 3, 9, 4, 0, 2, 7, 5, 8, 6]
print(insertionSort(arr_li))4、希尔排序
希尔排序是一种基于插入排序的排序算法,也被称为“缩小增量排序”。
工作原理:通过将待排序的数组分成若干个子序列,然后对这些子序列分别进行插入排序。这些子序列是原始数组中相隔固定增量(gap)的元素组成的。随着排序进行,增量逐渐减小,最终变为1,此时数组基本有序,最后一次插入排序即可完成排序。希尔排序的关键在于增量序列的选择,不同的增量序列会影响算法的性能。
时间复杂度取决于增量序列的选择,在O(n log2 n)与O(n2)之间。
空间复杂度为O(1),因为希尔排序在排序过程中只需要常数级别的额外空间来存储临时变量。
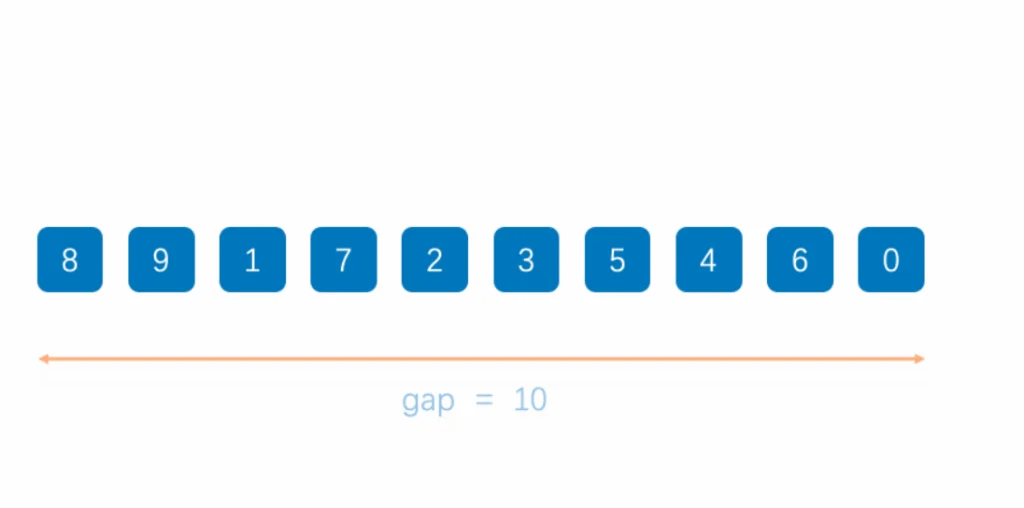
def shellSort(arr):
gap = len(arr) // 2
while gap > 0: # 每一次跳gap次取元素作为一组
for i in range(gap, len(arr)): # 对同一组内的元素进行插入排序 从后往前遍历已排序的元素并插入 56789
tempInd = i
while tempInd >= gap and arr[tempInd] < arr[tempInd - gap]:
arr[tempInd], arr[tempInd - gap] = arr[tempInd - gap], arr[tempInd]
tempInd -= gap
gap //= 2
return arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(shellSort(arr_li))5、归并排序
归并排序是一种分而治之的排序算法。
工作原理:
1、分割:将数组不断地对半分割,直到分割成单个元素的子数组。
2、合并:逐对合并相邻的子数组,并且在合并的过程中按顺序将元素放回到正确的位置上,直到整个数组被合并为一个完整的数组。
这两个步骤不断交替进行,直到排序完成。归并排序的关键在于合并的过程,它要求两个已经排好序的子数组被合并成一个排好序的数组。这是通过比较两个子数组的第一个元素,然后选择较小(或较大)的元素放入新的数组中来实现的。
归并排序的时间复杂度是O(n loge n),其中n是要排序的元素数量。
空间复杂度是O(n),因为归并排序需要额外的内存空间来存储临时的合并结果。
def mergeSort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
L, R = arr[:mid], arr[mid:] # 二路
mergeSort(L) # 同L=mergeSort(L)
mergeSort(R)
i = j = k = 0 # i为L的下标 j为R的下标 k为结果arr的下标
while i < len(L) and j < len(R):
if L[i] < R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
arr[k:] = L[i:] if i < len(L) else R[j:] # 如果L或R有剩余部分 将全部追加至尾部
return arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(mergeSort(arr_li))6、快速排序
快速排序是一种高效的排序算法,它采用了分治的策略。
其基本思想是选择一个基准元素(黄色条),然后将数组分割成两部分,一部分包含所有小于基准元素的值(绿色条),另一部分包含所有大于基准元素的值(紫色条)。
接着对这两部分递归地应用同样的排序方法。最终,当所有递归调用结束时,数组就变得有序。
快速排序通常比其他 O(n log n) 的排序算法更快,因为它的内部循环可以在大多数情况下很快地完成。
时间复杂度最好为O(n loge n)、最坏为O(n2)。空间复杂度为O(loge n)。
def quicklySort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0] # 每次都拿arr中第一个
less_than_pivot = [x for x in arr[1:] if x <= pivot] # 遍历出所有比第一个要小等于的
greater_than_pivot = [x for x in arr[1:] if x > pivot] # 遍历出所有比第一个要大的
return quicklySort(less_than_pivot) + [pivot] + quicklySort(greater_than_pivot) # 小的继续递归 + 中值(第一个元素) + 大的继续递归
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(quicklySort(arr_li))7、堆排序
堆排序是一种基于完全二叉堆数据结构的排序算法。
它分为两个步骤:建堆和排序。
建堆:将待排序的数组看作一个完全二叉树,并调整这棵树的结构,使其满足堆的性质。对于最大堆来说,父节点的值大于等于它的子节点的值;对于最小堆来说,父节点的值小于等于它的子节点的值。建立堆的过程一般从数组的一半处开始,依次向前进行调整。
排序:将堆顶元素(最大值或最小值)与堆的最后一个元素交换,然后将剩余元素重新调整为堆,再次取出堆顶元素并放到已排序部分的前面。重复这个过程直到整个数组有序。
堆排序是一个原地排序算法,不需要额外的辅助空间。
由于其需要的比较次数较多,因此在实际应用中相对于快速排序和归并排序的性能略有劣势。
堆排序的时间复杂度为 O(n loge n),其中 n 是要排序的元素数量。
由于堆排序是原地排序算法,所以它的空间复杂度为 O(1),即它不需要额外的辅助空间来进行排序。

def heapify(arr, n, i):
"""
对以i为根节点的子树进行堆调整
"""
largest = i
l, r = 2 * i + 1, 2 * i + 2 # 左右子节点
if l < n and arr[l] > arr[largest]: # 找出左右子节点和根节点中的最大值
largest = l
if r < n and arr[r] > arr[largest]:
largest = r
if largest != i: # 如果根节点不是最大值,交换根节点和最大值节点的值,并递归调整子树
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
def heapSort(arr):
"""
堆排序
"""
n = len(arr)
# 构建最大堆
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 逐步提取元素并重建堆
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 交换根节点与最后一个节点
heapify(arr, i, 0) # 对剩余的节点重新构建最大堆
return arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(heapSort(arr_li))8、计数排序
计数排序是一种非比较性质的排序算法,适用于元素范围不大的情况。
工作原理:计数排序通过遍历输入数组来计算每个元素出现的次数,并根据元素的值将其放入输出数组的正确位置。其工作原理如下:
1、找出待排序的数组中最大和最小的元素。
2、统计数组中每个值为 i 的元素出现的次数,存入数组 C 的第 i 项。
3、对所有的计数累加(从 C 中的第一个元素开始,每一项和前一项相加)。
4、反向填充目标数组:将每个元素 i 放在新数组的第 C(i) 项,每放一个元素就将 C(i) 减去 1。
计数排序的时间复杂度和空间复杂度均为 O(n+k),其中 n 是输入数组的大小,k 是输入的整数的范围(最大值减最小值加1)。
def countingSort(arr):
return [x for x in range(max(arr)+1) for _ in range(arr.count(x))]
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(countingSort(arr_li))9、桶排序
桶排序是一种简单高效排序算法。
工作原理:将要排序的数据分到有限数量的桶里,每个桶再分别排序(可能使用其他排序算法或递归地使用桶排序),最后将所有的桶合并起来。
在实现时,通常会根据数据的范围确定桶的数量,然后将数据分配到对应的桶中。桶内部可以使用插入排序等简单的排序算法进行排序。
最终,将所有桶的数据合并起来就得到了排好序的结果。
桶排序的时间复杂度取决于桶的数量和每个桶内部排序所使用的算法。
时间复杂度最好为O(n+k),最坏为O(n2)。空间复杂度为O(n+k),其中n是待排序元素的个数,k是桶的数量。

def bucketSort(arr):
# 创建空桶列表
buckets = [0] * (max(arr) + 1)
# 将元素放入对应的桶中
for num in arr:
buckets[num] += 1
# 合并排序好的桶中的元素
sorted_arr = []
for i in range(len(buckets)):
sorted_arr.extend([i] * buckets[i])
return sorted_arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(bucketSort(arr_li))10、基数排序
基数排序(Radix Sort)是一种非比较型整数排序算法
工作原理:按照数字的个位、十位、百位等位数上的值进行排序。它通过分配和收集的过程来实现排序。基数排序的具体步骤是:首先找出待排序数组中的最大值,确定其位数;然后利用计数排序(或桶排序)对每一位进行排序,最终完成整个数组的排序。这个过程会重复进行,直到所有位都被处理完毕,从而完成整个排序过程。基数排序适用于整数排序,且适用于整数位数较小的情况下,效率较高。
时间复杂度为O(nk),空间复杂度为O(n+k),其中n是数组中元素的个数,k是数字的最大值。

# 利用以下的计数排序
def countingSort(arr, exp):
return [x for x in range(10) for _ in range(arr.count(x // exp % 10))]
# 进行基数排序
def radixSort(arr):
max_num = max(arr)
exp = 1
while max_num // exp > 0:
arr = countingSort(arr, exp)
exp *= 10
return arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(radixSort(arr_li))完整代码
# 冒泡排序
def bubbleSort(arr):
for i in range(len(arr) - 1): # 来回推len(arr)-1次 i就是已经排序完成了多少到最后
for j in range(len(arr) - i - 1): # 每一遍遍历都会把未排序部分中最大的推到后面 对后已排序的部分不需要再排了 所以是len(arr)-i
if arr[j] > arr[j + 1]:
arr[j], arr[j + 1] = arr[j + 1], arr[j] # 大的往后排 置换数值
return arr
# 选择排序
def selectionSort(arr):
for i in range(len(arr) - 1):
minInd = i # 放置最小值的下标
for j in range(i + 1, len(arr)): # 跳过已经排序好的前i个 每次都到len(arr)最后一个元素
if arr[j] < arr[minInd]:
minInd = j
# 每一次大遍历后 对比剩余部分最小值和遍历起始下标值
if minInd != i:
arr[i], arr[minInd] = arr[minInd], arr[i]
return arr
# 插入排序
def insertionSort(arr):
for i in range(len(arr)): # 大遍历次数len(arr)
current = arr[i] # 每次拿出一个current数组 依次和前面的作比较
preInd = i - 1 # current要和这个下标的值对比 第一次是和下标-1的对比 即直接将current放在preInd前(作为排序好的首位)
while preInd >= 0 and arr[preInd] > current:
arr[preInd + 1] = arr[preInd]
preInd -= 1 # 继续往前对比
arr[preInd + 1] = current # 直到前面没有比current大的了 将current放进刚对比的arr[preInd]前
return arr
# 希尔排序
def shellSort(arr):
gap = len(arr) // 2
while gap > 0: # 每一次跳gap次取元素作为一组
for i in range(gap, len(arr)): # 对同一组内的元素进行插入排序 从后往前遍历已排序的元素并插入 56789
tempInd = i
while tempInd >= gap and arr[tempInd] < arr[tempInd - gap]:
arr[tempInd], arr[tempInd - gap] = arr[tempInd - gap], arr[tempInd]
tempInd -= gap
gap //= 2
return arr
# (二路)归并排序
def mergeSort(arr):
if len(arr) <= 1:
return arr
mid = len(arr) // 2
L, R = arr[:mid], arr[mid:] # 二路
mergeSort(L) # 同L=mergeSort(L)
mergeSort(R)
i = j = k = 0 # i为L的下标 j为R的下标 k为结果arr的下标
while i < len(L) and j < len(R):
if L[i] < R[j]:
arr[k] = L[i]
i += 1
else:
arr[k] = R[j]
j += 1
k += 1
arr[k:] = L[i:] if i < len(L) else R[j:] # 如果L或R有剩余部分 将全部追加至尾部
return arr
# 快速排序
def quicklySort(arr):
if len(arr) <= 1:
return arr
else:
pivot = arr[0] # 每次都拿arr中第一个
less_than_pivot = [x for x in arr[1:] if x <= pivot] # 遍历出所有比第一个要小等于的
greater_than_pivot = [x for x in arr[1:] if x > pivot] # 遍历出所有比第一个要大的
return quicklySort(less_than_pivot) + [pivot] + quicklySort(greater_than_pivot) # 小的继续递归 + 中值(第一个元素) + 大的继续递归
# 堆排序-堆节点遍历
def heapify(arr, n, i):
"""
对以i为根节点的子树进行堆调整
"""
largest = i
l, r = 2 * i + 1, 2 * i + 2 # 左右子节点
if l < n and arr[l] > arr[largest]: # 找出左右子节点和根节点中的最大值
largest = l
if r < n and arr[r] > arr[largest]:
largest = r
if largest != i: # 如果根节点不是最大值,交换根节点和最大值节点的值,并递归调整子树
arr[i], arr[largest] = arr[largest], arr[i]
heapify(arr, n, largest)
# 堆排序
def heapSort(arr):
"""
堆排序
"""
n = len(arr)
# 构建最大堆
for i in range(n // 2 - 1, -1, -1):
heapify(arr, n, i)
# 逐步提取元素并重建堆
for i in range(n - 1, 0, -1):
arr[i], arr[0] = arr[0], arr[i] # 交换根节点与最后一个节点
heapify(arr, i, 0) # 对剩余的节点重新构建最大堆
return arr
# 计数排序
def countingSort(arr):
return [x for x in range(max(arr) + 1) for _ in range(arr.count(x))]
# 桶排序
def bucketSort(arr):
# 创建空桶列表
buckets = [0] * (max(arr) + 1)
# 将元素放入对应的桶中
for num in arr:
buckets[num] += 1
# 合并排序好的桶中的元素
sorted_arr = []
for i in range(len(buckets)):
sorted_arr.extend([i] * buckets[i])
return sorted_arr
# 基数排序-内嵌计数排序
def countingSort(arr, exp):
return [x for x in range(10) for _ in range(arr.count(x // exp % 10))]
# 基数排序
def radixSort(arr):
max_num = max(arr)
exp = 1
while max_num // exp > 0:
arr = countingSort(arr, exp)
exp *= 10
return arr
if __name__ == '__main__':
arr_li = [8, 9, 1, 7, 2, 3, 5, 4, 6, 0]
print(radixSort(arr_li))
Comments 2 条评论
The Beatles – легендарная британская рок-группа, сформированная в 1960 году в Ливерпуле. Их музыка стала символом эпохи и оказала огромное влияние на мировую культуру. Среди их лучших песен: “Hey Jude”, “Let It Be”, “Yesterday”, “Come Together”, “Here Comes the Sun”, “A Day in the Life”, “Something”, “Eleanor Rigby” и многие другие. Их творчество отличается мелодичностью, глубиной текстов и экспериментами в звуке, что сделало их одной из самых влиятельных групп в истории музыки. Музыка 2024 года слушать онлайн и скачать бесплатно mp3.
老铁666